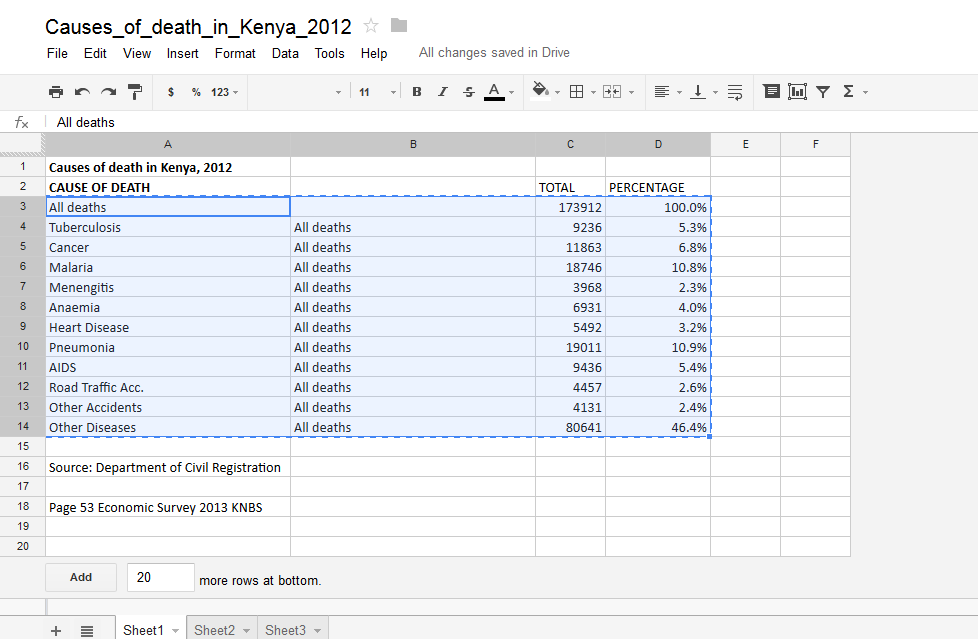
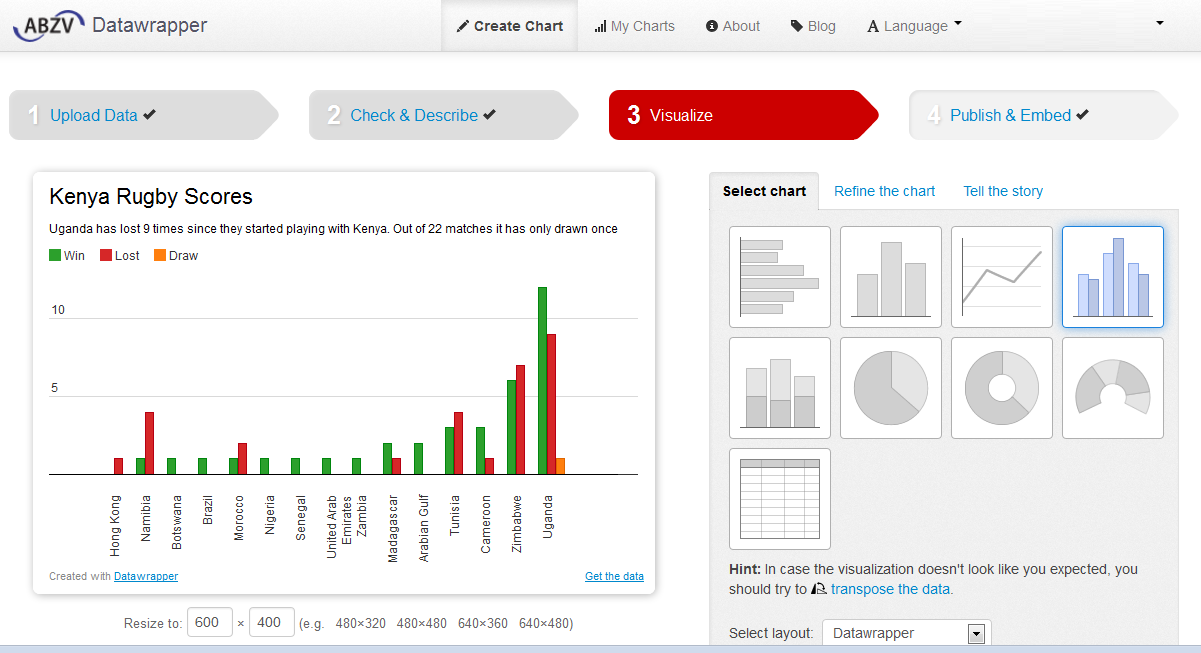
DATA CLEANING
Data journalism workshops can make the data journalism process seem much faster and more straight-forward than it really is. In reality, most data doesn’t arrive organized and error-free. Most data is messy. Before beginning any kind of analysis, the data needs to be cleaned. Data cleaning is a process data journalists use to detect, correct or delete inaccurate, incomplete, or erroneous data with an aim of improving data quality. Examples of errors commonly found in data are:
1. Wrong date formats or incorrect dates like 30th February, 2013.
2. Unknown characters.
3. Missing data.
4. Spaces before and after values.
5. Data that is beyond rage for example, age of a human being recorded as 879 years.
6. Inconsistency.
7. Other errors.
Data cleaning is also known as:
1. Error Checking
2. Error Detection
3. Data Validation
4. Data Cleansing
5. Data Scrubbing
6. Error Correction
The process of data cleaning may include:
1. Format checks
2. Completeness checks
3. Reasonableness checks.
4. Limit checks
5. Review of the data to identify outliers
6. Assessment of data by subject area experts (e.g. Doctors assessing Kenya Health at a Glance data)
These processes usually result in flagging, documenting and subsequent checking and correcting of suspect records. In advanced data management, validation checks may also involve checking for compliance against applicable standards, rules, and conventions.
The general framework for data cleaning is:
1. Define and determine error types.
2. Search and identify error instances.
3. Correct the errors.
4. Document error instances and error types.
5. Modify data entry procedures (or regular expressions in during data scrapping) to reduce future errors.
Data journalists often use these tools for data cleaning:
1. Open Refine.
2. Excel.
Advanced data cleaning may be done in SQL, STATA, SAS and other Statistical applications to detect errors. If errors are well documented and analyzed, it can help data journalists and program managers to prevent more errors from happening.
HOW TO USE OPEN REFINE TO CLEAN DATA
We shall go through the following steps to learn how to use Open Refine to clean data.
• Introduction
• Basic functionalities
• Advanced functionalities
• Summary
Introduction
Initially developed by Google, Open Refine is now it is completely maintained by volunteers.
• Open Refine is a desktop application (installed in our computers) that help us understand and clean datasets.
• Refine has a web interface that launches a browser but works locally.
• Open Refine does not work on Internet Explorer.
What is Open Refine designed for?
• Understanding the dataset through filters and facets.
• Cleaning typos and adapt data formats.
• Derive new data based on original data – e.g. Generating new data column based on a formula from the already existing data columns.
• Reuse transformations – this is being able to save the steps in a code such that when the second dataset in the same format is imported, the code is ran at once.
What is Open Refine not designed for?
• Adding new information to a dataset.
• Making complex calculations (Spreadsheet software is better, like, MS Excel).
• Data visualization (there are other tools available to do that).
• Datasets with a huge column number greater than 80 (OpenRefine does column-based operations so it would be tedious).
Example
To understand how Open Refine works let’s look to an example;
1. Download and install Open Refine here. http://openrefine.org/download.html
2. Launch OpenRefine.
3. Find the project named: “F1Results2012-2003. google-refine.tar.gz”
4. Import the project into Refine.
Basic functionalities of Open Refine
Facets: These are like Excel filters but with counters.
Types:
• Text
• Numeric
• Timeline
• Custom (Facet by blank, Facet by error, etc.)
Functionality:
• Applying a filter enables us to work onthe subset of data we are interested in.
• Add columns based on another column to modify all data in column
• Split columns by a character separator. For example, split:”Surname, Name” into the two columns “Surname” and “Name”
Figure 1: The use of Facets, Text Filters and Clustering
Figure 2: How to Split a column
We can use Open Refine to:
• Rename/Remove columns.
• Execture common transformations.
• Remove white space.
• Data type conversion (number to text, etc.)
• Lowercase, uppercase, title case.
• Cut parts of a text (substring).
• Replace parts of a text (replace)
• Fill down adjacent cells
• Remove “matched” rows (after filtering some rows or selecting a value on a facet we can remove only the matched rows).
Figure 3: Shows how to edit cells through common transforms.
NOTE: Most functionality is under common transforms.
Figure 4: shows how to remove all matching rows.
Clustering:
Helps to find similarities within texts in order to identify and standardize differences in spelling and format of entries. For example, identify that “Kakamega,” “Kaka mega” and “Kakamega County” are all the same. of the different clustering algorithms from finding very close matches to distant matches. It does not cluster values automatically but instead it shows the clusters to the user. So it is our decision in the end whether the different entries should all have a uniform name.
Figure 4: How to use clustering
Advanced functionalities to explore include:
• Obtaining new data through a web service.
• Retrieve coordinates based on address.
• Determine the language of a text.
• Get data from another project based on a common column (Like MS Vlookup).
• Using “cell.cross”
References
Google tutorials:
1. Introduction
2. Data transformation
3. Data augmentation
Documentation:
• User manual
• Google Refine Expression Language (all the functions available for us to use on our transformations).









{kind=link}